False Sharing
False Sharing이란 무엇입니까 설명 작성중....
캐시 라인 크기
int32_t 값의 데이터를 가져오고 싶습니다. 따라서 코드를 int32_t newValue = originValue; // originValue는 int32_t로 판단 하겠습니다. 이렇게 작성했다고 하면 코드 상으로만 보면 메모리에 있던 originValue를 가져 와서 그 값을 newValue에 대입하는 것으로 보입니다. 하지만 하드웨어에서는 단순히 이 일만 처리 하지 않습니다. 우리의 눈에 보이지 않은 여러 일을 처리 한 후에 결과를 얻을 수 있습니다. 때로는 모르는게 약일 수도 있긴 합니다만 지금은 탐구하고 있으니 한번 살펴 보도록 하겠습니다
최신 시스템은 더 빠른 메모리 접근을 위해 다단계 캐싱을 사용합니다. 일반적으로 L1, L2, L3의 세 계층의 캐시가 있습니다. 현재 CPU가 해당 캐시를 사용하는지 저장 공간은 어느 정도인지는 직접 확인할 수 있습니다. 기본적으로 크기 순(L3 > L2 > L1)에 따라서 접근 속도가 느립니다.(L1 > L2 > L3) 그리고 CPU 코어 각각이 L1, L2 캐시를 가지고 있고 L3 부터가 공용으로 알고 있습니다. 그래서 이러한 구조 때문에 CPU는 데이터의 메모리에 접근할 때 가장 먼저 L1 캐시를 확인합니다. 그래서 캐시의 적중이 높을 수록 더 빠르게 데이터를 가져올 수 있게 됩니다. 그렇지 않으면 캐시를 찾다가 결국 L3를 넘어서 메인 메모리를 직접 찾아야 할 수도 있으니까요. 그러면 당연히 L1 캐시에서 데이터를 가져오는 것보다 느릴 것입니다. 컴퓨터 과학에서 성공하는 것은 Cache Hit라고 하고 결국 메인 메모리까지 가서 데이터를 찾는 것은 Cache Miss라고 합니다. 이 규칙을 Multi Core에서도 잘 작동하게 하려면 코어 별로도 캐시 규칙이 필요합니다. 이를 Cache Coherence라고 합니다. 하지만 여기서 다루기에는 너무 내용이 방대하기 때문에 이 규칙에 의해서 예시 코드의 정확한 측정이 안되므로 volatile 키워드를 사용할 것이라는 것만 말씀드리고 넘어 가도록 하겠습니다.
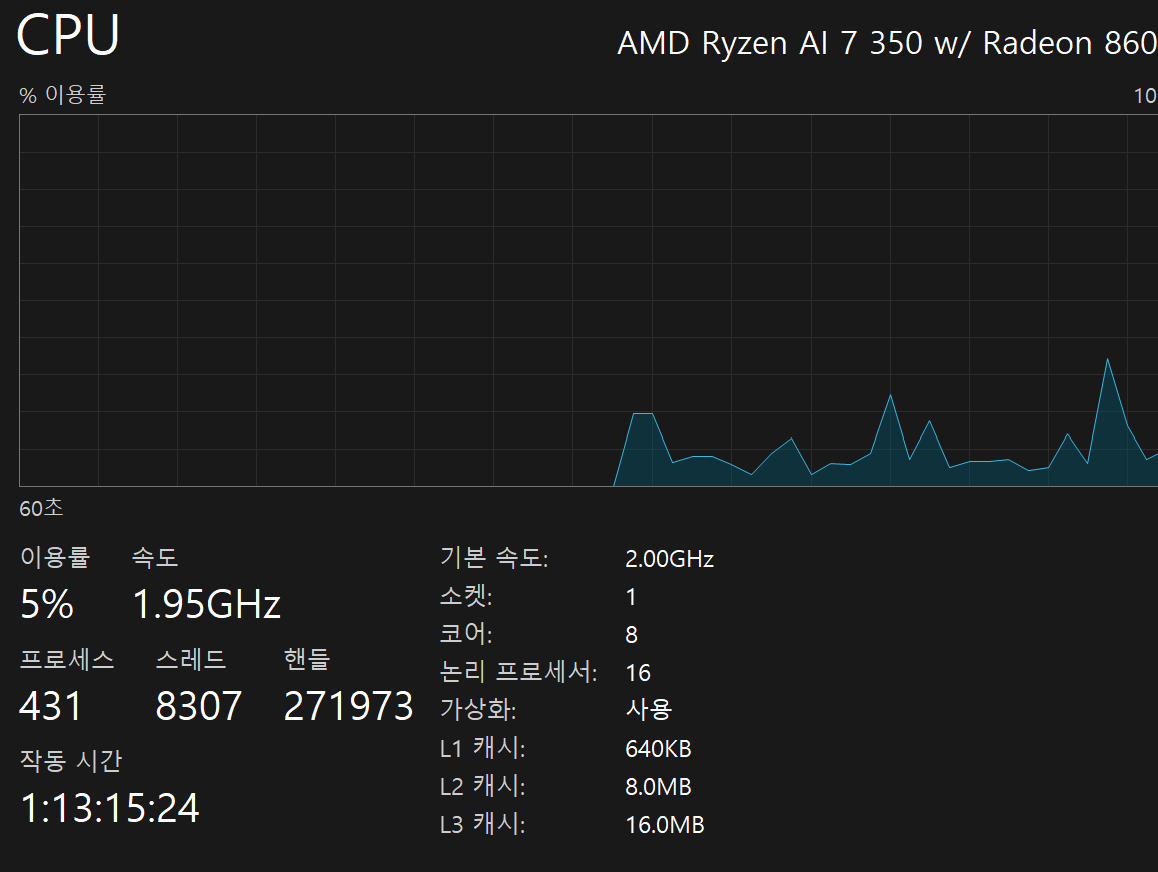 내 CPU 캐시 사이즈...
내 CPU 캐시 사이즈...
관련이 있는 이야기로 다시 돌아오면 캐시 혹은 메모리에서 데이터를 가져올 때 우리가 원하는 int32_t의 크기만큼만 읽는 것은 아닙니다. 캐시를 통해 더 빠르게 수행하기 위해 노력하는 것처럼 데이터를 가져올 때도 더 빠르게 처리 하기 위해 정해진 것만 가져오는 것이 아니라 그 주변 주소의 데이터까지 가져 와서 처리합니다. 이것은 공간적 지역성(Spatial Locality) 이라고 합니다. C++에서 어느 정도 크기를 가지고 같이 읽어오는지는 알 수 있긴 합니다. 그것은 std::hardware_destructive_interference_size 입니다. 일반적으로는 x86 아키텍쳐에서는 64바이트, Apple 계열은 128바이트로 알려져 있습니다. hardware_destructive_interference_size는 캐시 라인 충돌을 피하기 위해 서로 다른 코어에서 이 정도는 떨어져 있어야 한번에 가져오는 데 포함이 안되도록 하는 크기 값 입니다. hardware_constructive_interference_size값도 있습니다. 이것은 True Sharing을 통해 이 크기 보다 안쪽이라면 캐시 라인에서 한번에 값을 가져 오기 때문에 한번에 값을 다 읽어올 수 있는 크기 입니다. MSVC에서는 전부 다 64로 constexpr 처리된 값이긴 하네요. 결국 이 캐시라인이라고 하는 크기는 공간적 지역성을 확보하기 위한 것이라고 할 수 있습니다.
 하드코딩...
하드코딩...
이러한 설명을 통해서 이제 Multi-Core에서 발생할 수 있는 문제인 False Sharing에 대해서 이해할 수 있을 것입니다. 이것이 싱글 스레드가 아닌 멀티 스레드에서 인접한 여러 변수를 처리 할 때 발생할 수 있는 문제 입니다. Thread1와 Thread2가 있다고 가정하겠습니다. Thread1에서 A의 변수를 접근해서 인접해 있는 변수 B 까지 L1 캐시에 값이 등록이 되었다고 하겠습니다. 이 때 Thread2에서 B의 변수값을 접근해서 변경하게 되면 Thread1의 L1 캐시도 영향을 받게 됩니다. 앞서 언급한 Cache Coherence(MESI 프로토콜)에 의해서 프로토콜에 의해서 캐시 무효화를 전파 합니다. 실제로 변수 B에 접근은 하지 않았지만 캐시 라인 크기 만큼 데이터를 적재 했기 때문입니다. 그래서 결국 Thread1이 A변수를 다시 접근 하게 되면 L1캐시가 아니라 메인 메모리까지 접근을 해야 합니다. 이 상황이 False Sharing. 즉 거짓 공유 입니다.
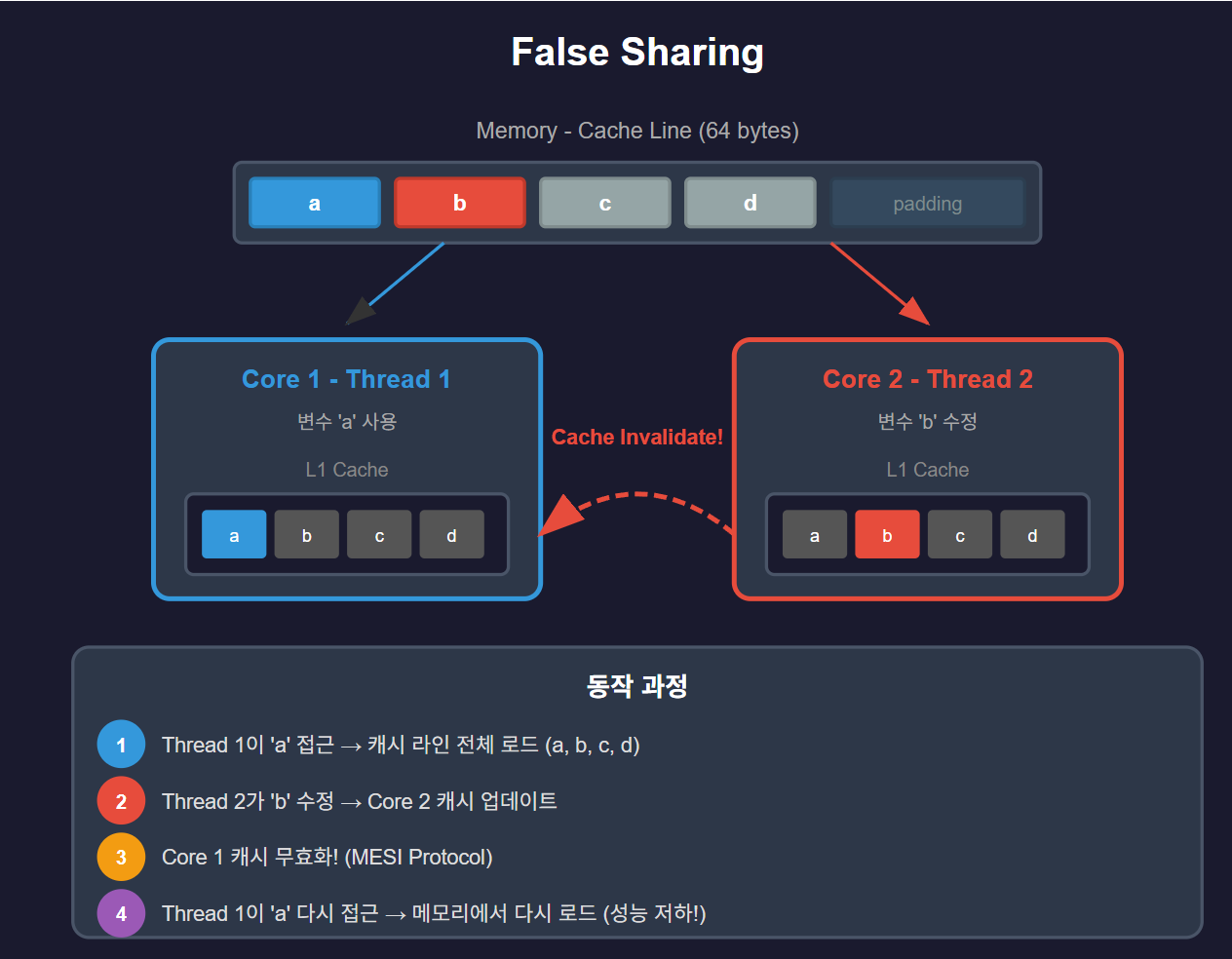 해당 그림은 Claude를 통해 생성 했습니다.
해당 그림은 Claude를 통해 생성 했습니다.
이것은 쉽게 예시 코드로 확인할 수 있습니다. False Sharing에 맞춰서 크기를 인접에 선언한 변수를 두 스레드를 통해 계속 값을 바꾸는 것과 alignas 키워드를 사용해서 False Sharing을 피하는 형태 입니다. alignas 지정자는 메모리에 있는 형식 또는 개체의 맞춤을 변경합니다. 물론 Heap 할당시에도 메모리를 정렬할 수 있습니다. 이것은 C++17의 aligned_alloc 기능입니다. Linux 내부에서는 #define ALIGN(x, a) (((x) + ((a) - 1)) & ~((a) - 1)) 이런 식으로 매크로를 만들어서 사용하기도 합니다.
직접 코드로 돌려보기
먼저 테스트 첫번째로는 alignas를 활용해서 비교해 볼 것입니다. Single Thread의 경우 스레드 생성과 닫는 코드에 차이가 크게 나지 않도록 스레드 1개를 만들어서 처리하도록 했습니다. 따라서 스레드 1개분 생성 제거 차이나는 시간은 어느 정도 감안을 하면 될것 같습니다. 코드는 아래와 같습니다.
constexpr int32_t CACHE_SIZE = std::hardware_destructive_interference_size;
constexpr int32_t ITERATIONS = 100'000'000;
struct NormalCounter
{
volatile int32_t _count1 = 0;
volatile int32_t _count2 = 0;
};
struct AlignedCounter
{
alignas( CACHE_SIZE ) volatile int32_t _count1 = 0;
alignas( CACHE_SIZE ) volatile int32_t _count2 = 0;
};
unsigned __stdcall testCounterSingleThreadFunc( void* arguments ) noexcept
{
NormalCounter* counter = static_cast< NormalCounter* >( arguments );
for ( int32_t ii = 0; ii < ITERATIONS; ++ii )
{
counter->_count1 += 1;
}
for ( int32_t ii = 0; ii < ITERATIONS; ++ii )
{
counter->_count2 += 1;
}
_endthreadex( 0 );
return 0;
}
unsigned __stdcall testBadCounter1ThreadFunc( void* arguments ) noexcept
{
NormalCounter* counter = static_cast< NormalCounter* >( arguments );
for ( int32_t ii = 0; ii < ITERATIONS; ++ii )
{
counter->_count1 += 1;
}
_endthreadex( 0 );
return 0;
}
unsigned __stdcall testBadCounter2ThreadFunc( void* arguments ) noexcept
{
NormalCounter* counter = static_cast< NormalCounter* >( arguments );
for ( int32_t ii = 0; ii < ITERATIONS; ++ii )
{
counter->_count2 += 1;
}
_endthreadex( 0 );
return 0;
}
unsigned __stdcall testGoodCounter1ThreadFunc( void* arguments ) noexcept
{
AlignedCounter* counter = static_cast< AlignedCounter* >( arguments );
for ( int32_t ii = 0; ii < ITERATIONS; ++ii )
{
counter->_count1 += 1;
}
_endthreadex( 0 );
return 0;
}
unsigned __stdcall testGoodCounter2ThreadFunc( void* arguments ) noexcept
{
AlignedCounter* counter = static_cast< AlignedCounter* >( arguments );
for ( int32_t ii = 0; ii < ITERATIONS; ++ii )
{
counter->_count2 += 1;
}
_endthreadex( 0 );
return 0;
}
int main( void )
{
std::cout << "Suggested cache line size: " << CACHE_SIZE << " bytes" << std::endl;
HANDLE threads[ 2 ];
unsigned threadID1;
unsigned threadID2;
NormalCounter normalCounter = {};
NormalCounter singleCounter = {};
AlignedCounter alignedCounter = {};
{
std::chrono::steady_clock::time_point start = std::chrono::high_resolution_clock::now();
unsigned threadID;
HANDLE thread = ( HANDLE )_beginthreadex( NULL, 0, testCounterSingleThreadFunc, &singleCounter, 0, &threadID);
WaitForSingleObject( thread, INFINITE );
CloseHandle( thread );
std::chrono::steady_clock::time_point end = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds duration = std::chrono::duration_cast( end - start );
std::cout << "Single Thread Test : " << duration.count() << "ms" << std::endl;
}
{
std::chrono::steady_clock::time_point start = std::chrono::high_resolution_clock::now();
threads[ 0 ] = ( HANDLE )_beginthreadex( NULL, 0, testBadCounter1ThreadFunc, &normalCounter, 0, &threadID1 );
threads[ 1 ] = ( HANDLE )_beginthreadex( NULL, 0, testBadCounter2ThreadFunc, &normalCounter, 0, &threadID2 );
WaitForMultipleObjects( 2 ,threads, TRUE, INFINITE );
CloseHandle( threads[ 0 ] );
CloseHandle( threads[ 1 ] );
std::chrono::steady_clock::time_point end = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds duration = std::chrono::duration_cast( end - start );
std::cout << "Not Aligned Test : " << duration.count() << "ms" << std::endl;
}
{
std::chrono::steady_clock::time_point start = std::chrono::high_resolution_clock::now();
threads[ 0 ] = ( HANDLE )_beginthreadex( NULL, 0, testGoodCounter1ThreadFunc, &alignedCounter, 0, &threadID1 );
threads[ 1 ] = ( HANDLE )_beginthreadex( NULL, 0, testGoodCounter2ThreadFunc, &alignedCounter, 0, &threadID2 );
WaitForMultipleObjects( 2 ,threads, TRUE, INFINITE );
CloseHandle( threads[ 0 ] );
CloseHandle( threads[ 1 ] );
std::chrono::steady_clock::time_point end = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds duration = std::chrono::duration_cast( end - start );
std::cout << "Aligned Test : " << duration.count() << "ms" << std::endl;
}
return 0;
}
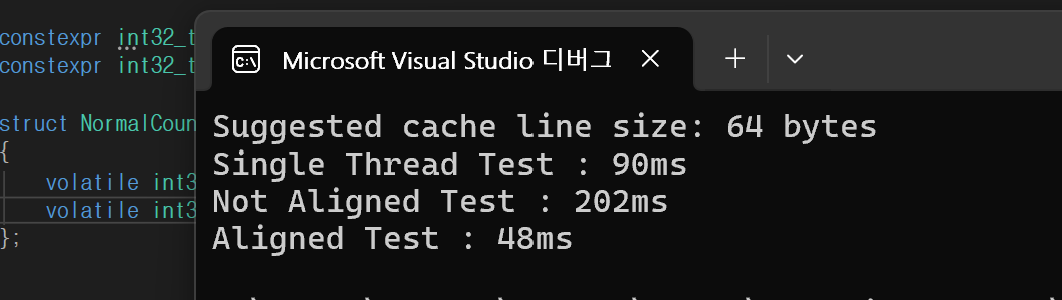 alignas를 통한 false-sharing 테스트 결과
alignas를 통한 false-sharing 테스트 결과
두번째 메모리 정렬에 따른 테스트 작성중...