데이터 레이크(Data Lake)란 무엇입니까
데이터 레이크(Data Lake)의 일반적인 정의는 환경에 따라 다르지만 일반적으로는 다음과 같은 정의로 설명하고 있습니다. 데이터 레이크는 구조화 되거나 구조화 되지 않은 모든 데이터(all your structured and unstructured data)를 다루기 위한 중앙 집중형 저장소(centralized repository) 입니다. 구조화 되지 않은 것은 기본 파일이나 이미지 동영상 등의 형태를 예로 들 수 있습니다. 그리고 구조화된 데이터는 일정 형식을 따르는 것으로 Apache Parquet, Apache Avro와 같이 HDFS에서 적합한 형식이나 데이터베이스 테이블과 같은 형태를 말합니다. 이와 같이 여러 형태의 데이터를 처리하기 때문에 기존의 개념인 데이터 웨어하우스(Data Warehouse)와 상호 보완적인 기능을 수행할 수 있습니다. 특히 ML Pipeline를 구축하거나 대규모 Deeplearning 학습에 필요한 데이터를 제공할 필요성이 많아진 요즘에 데이터 레이크의 필요성은 증가한다고 볼 수 있습니다. 또한 기존의 Apache Hadoop과 같은 데이터 웨어하우스가 담당하던 데이터 처리 또한 기본적으로 수행할 수 있습니다.
Apache Iceberg
Netflix에서는 거대한 데이터 규모의 처리 문제를 해결하기 위해 한 프로젝트를 진행 했습니다. 그 프로젝트는 목적에 맞게 문제를 해결했고 그 이후에 오픈소스로 변경되어서 Apache 프로젝트에 합류 합니다. 이 프로젝트의 현재 이름은 Apache Iceberg 입니다. Apache Iceberg는
설명 보충중....
Apache Iceberg의 설치와 실행
Apache Iceberg는 다양한 방법으로 실행할 수 있는데 공식 사이트에서는 Apache Spark와 Apache Hive를 통해서 실행하는 방법을 소개하고 있습니다. 저는 Apache Spark를 통해 실행 하도록 하겠습니다. 먼저 Apache Spark를 준비해서 Apache Iceberg를 실행할 수 있도록 준비하겠습니다. Spark는 설치해서 Spark-shell을 통해 실행할 수 있습니다. Spark 실행은 내부의 start-all.sh 명령어를
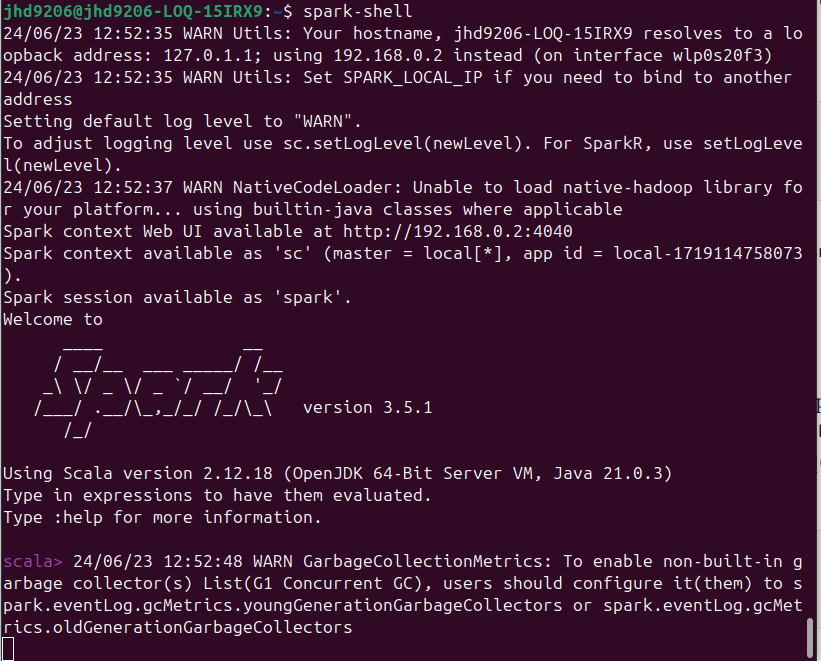 Spark Shell 실행
Spark Shell 실행
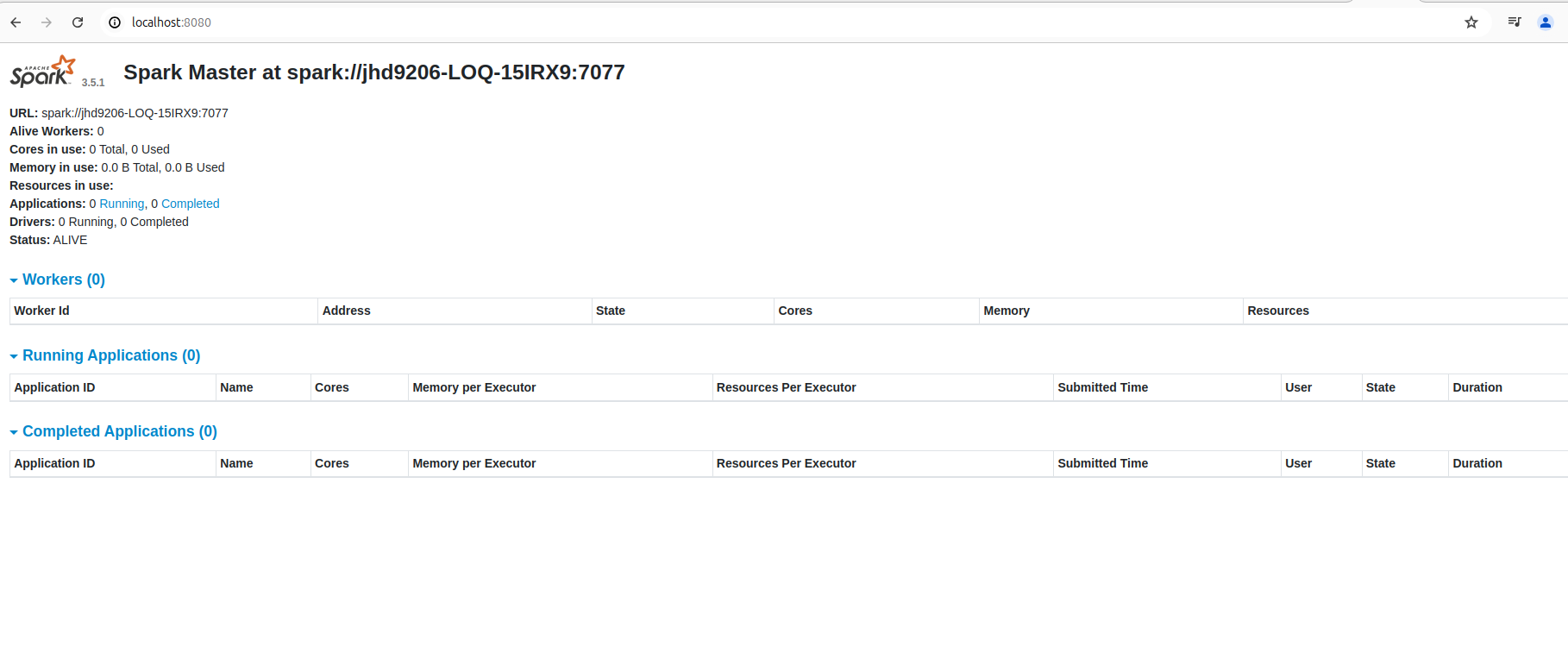 Spark Node UI Page
Spark Node UI Page
그 이후에 Spark-Shell을 사용해서 Apache Iceberg를 실행 하겠습니다. 해당 실행을 위해서 iceberg-spark-runtime을 설치하고 Spark의 기본 제공 카탈로그에 Iceberg 테이블에 대한 지원을 추가해야 합니다. 공식 사이트에서는 설치와 설정에 관련한 shell 명령어를 추천하는데 해당 방식으로 진행하겠습니다.
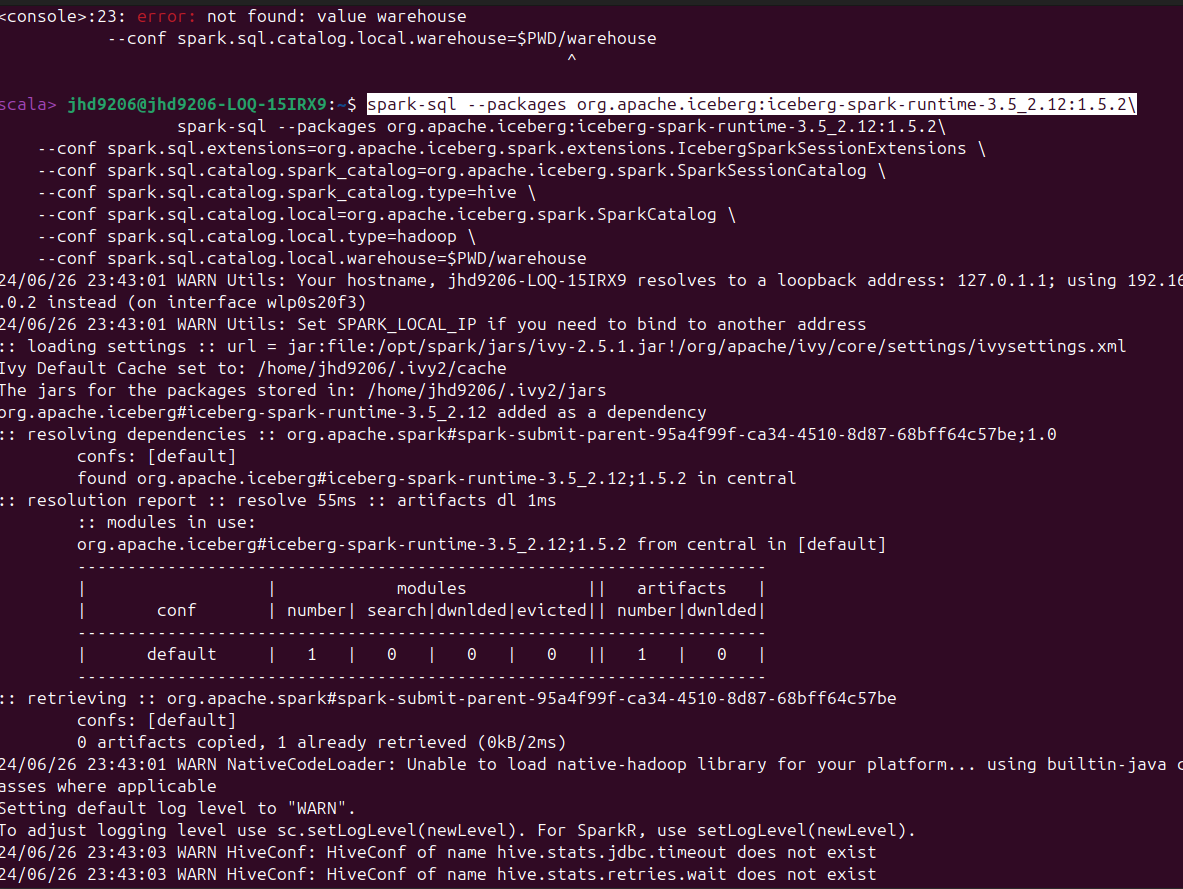 Spark Shell로 iceberg-spark-runtime 설치 및 환경 설정
Spark Shell로 iceberg-spark-runtime 설치 및 환경 설정
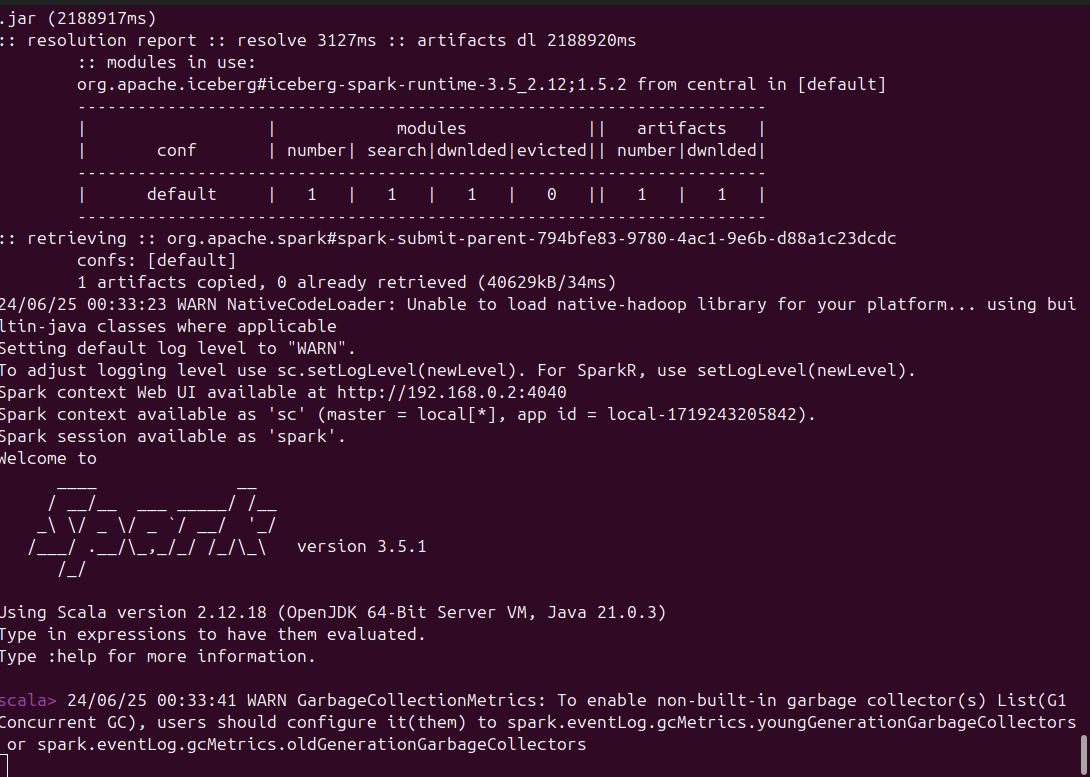 iceberg-spark-runtime 설치 및 환경 설정 결과
iceberg-spark-runtime 설치 및 환경 설정 결과
이 단계 까지 진행 했다면 iceberg 관련 기능을 사용할 수 있습니다. 제일 간단한 방법은 Iceberg 테이블을 생성하는 것입니다. 방법은 명령어 마지막에 USING iceberg;를 추가하는 것인데 이 방법으로 테이블을 생성 하도록 하겠습니다.
 Iceberg 테이블 생성
Iceberg 테이블 생성
Iceberg 테이블이 성공적으로 생성되었다면 데이터를 추가해서 결과를 보도록 하겠습니다. 먼저 INSERT를 통해서 데이터를 추가한 이후에 SELECT를 통해서 정상적으로 데이터를 확인할 수 있는지 확인하겠습니다. 결과는 아래와 같습니다
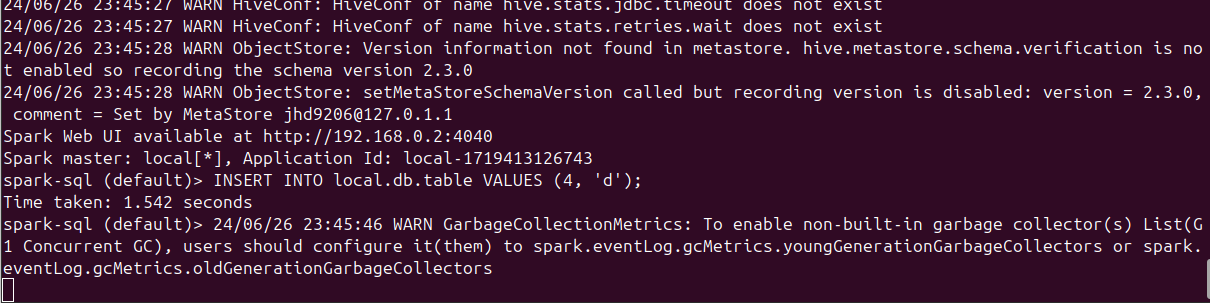 Iceberg 테이블에 INSERT 쿼리 실행
Iceberg 테이블에 INSERT 쿼리 실행
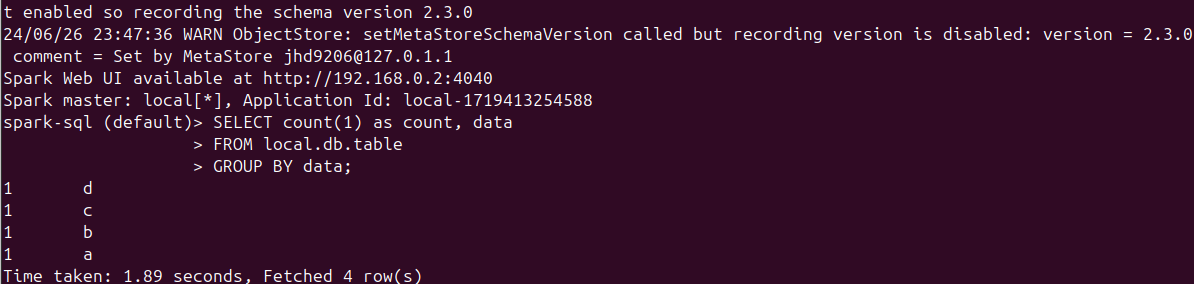 Iceberg 테이블에 SELECT 쿼리 실행
Iceberg 테이블에 SELECT 쿼리 실행
작업이 성공적으로 되어서 결과를 확인할 수 있다는 것을 cmd 창을 통해서 확인할 수 있습니다. 그리고 이외에도 Spark Task UI를 통해서 웹으로도 확인할 수 있습니다. 작업 내역 확인은 아래와 같습니다
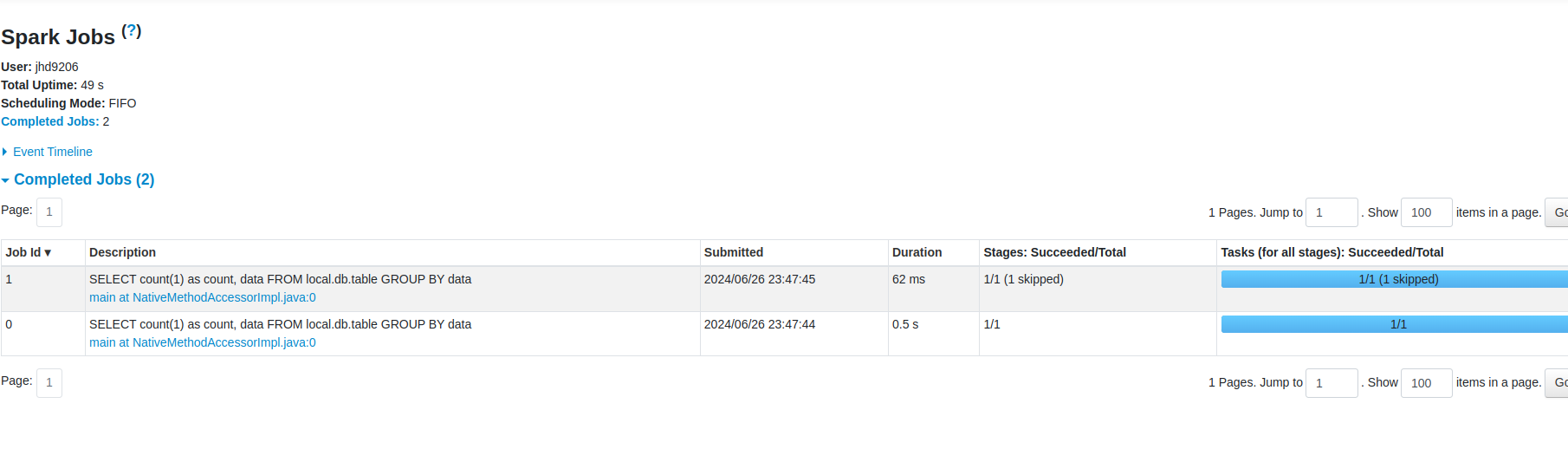 쿼리 테스크 Spark UI를 통해 확인
쿼리 테스크 Spark UI를 통해 확인
테이블 변경 / snapshot, history 등 추가중....